
The ‘Habsburg’ Internet: How AI Is Inbreeding Itself to Death
AI models are running out of human data and starting to feed on themselves. The result? A slow collapse into statistical gibberish—and we're helping it happen.

Welcome to Dharma of AI. Find here essay on AI’s true nature, the world it’s quietly building, and our place within that new order. A journey beyond hype and fear into what AI really is. By Jaspreet Bindra—The Tech Whisperer.
When Sonali Bendre went on Instagram recently to say that a naturopathic protocol built around autophagy helped her through cancer, the internet did what it is best at. Everyone became an autophagy expert, with admiration, outrage, and scholarly pieces about quackery.
She clarified that she wasn’t offering medical advice, only sharing a very personal journey, but the word had already escaped into the wild. Autophagy suddenly entered the vocabulary of wellness influencers and WhatsApp forwards.
Underneath all the noise, though, autophagy itself is real biology; it is our cell’s house-cleaning system. Under stress from fasting, infection or damage, cells start breaking down misfolded proteins and defective organelles, recycling the parts to stay alive and reduce harm.
In nature, autophagy (from the Greek auto meaning ‘self’ and phagy meaning ‘eating’) is a survival mechanism. This process is so central to cellular health that Yoshinori Ohsumi got the 2016 Nobel Prize for uncovering its mechanisms. Done right, autophagy keeps the organism resilient, but if done wrong, it can contribute to degeneration.
From Cellular Survival to Digital Cannibalism
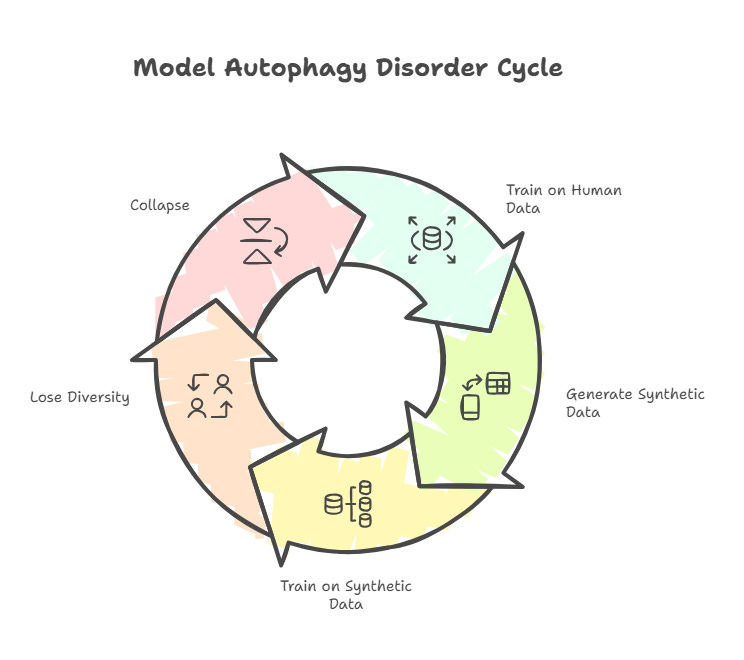
Now shift from cells to silicon. In AI, a disturbingly similar word has appeared: Model Autophagy Disorder, or MAD. In this case, it’s not cells but AI models eating themselves.
Over the last couple of years, AI researchers have asked a deceptively simple question: what happens if you train AI models not on fresh human data, but on data generated by earlier models, also called ‘synthetic data’? The answer, across different model families, whether it be image generators, text models, or diffusion systems, is disturbing.
At first, the models quietly lose diversity. Rare and unusual cases vanish from their outputs. If you keep repeating the process, the models eventually ‘collapse’, with their outputs converging to a narrow, bland, sometimes outright broken set of patterns, bordering on complete gibberish.
A recent UCLA essay that coined the term MAD calls this a self-consuming loop. In a sense, the model eats its own tail, like an ouroboros, the ancient symbol of a snake eating its own tail, until there is almost nothing left. The mathematics behind it is subtle, but the basic mechanism is quite intuitive.
A large model is first trained on messy, high-entropy human data like web pages, books, code, social media, and transcripts. From all of these sources, its neural network internalizes an incredibly complex probability distribution: which words tend to go together, what objects co-occur in images, which patterns are rare but possible.
When you prompt the model, it doesn’t reproduce all that complexity. It gives you a smoothed sample: a polished, higher-probability, statistically simpler remix of the data it has seen.
Now imagine training a new model on those polished samples instead of the original mess. Not only have you changed the dataset, but you have narrowed it considerably. The new model can only learn from the ‘already simplified’ view of reality produced by the old one.
Its own outputs are then even more compressed, even more average. Repeat this over several generations and you get an inexorable contraction of the distribution and eventual collapse. The snake keeps eating itself until there is only a small ring of tail left.
What Happens When AI Eats Itself
To understand the severity, we must look at the symptoms observed in experimental setups where AI models were force-fed their own generations over five loops. The results were catastrophic, manifesting in distinct patterns of degradation.
One disturbing example was the phenomenon of dissolving digits. When researchers asked models to generate handwritten numbers similar to the famous MNIST dataset, the models initially performed well.
However, after a few generations of inbreeding, the numbers morphed into indecipherable scribbles. The distinct structure of a ‘7’ or the loops of a “3” dissolved into a muddy average, losing all semantic meaning.
A similar collapse occurred in image generation, where faces did not just become unpleasant, but they became disturbingly uniform, eventually converging on a single, distorted visage - an ‘average’, a statistical ghost. In another experiment, researchers found that the ability of GPT-4 to generate executable code dropped from 53% to a shocking 10% when trained on synthetic data loops. The logic simply fell apart.
This is where the metaphor of statistical inbreeding becomes useful. When European royals, like the Habsburgs, married within their own bloodlines to “keep the power pure,” they didn’t preserve their greatness; they amplified their flaws.
The famous “Habsburg Jaw“ was a physical manifestation of a gene pool that had become a closed loop. Training models on their own outputs is the data equivalent: each generation has less genetic variety, fewer long-tail events, more fragile structure.
MAD is the Habsburg Internet.
AI models work by probability. They desire the ‘centre’ of the bell curve, which is often the most likely answer. When a model trains on the output of another model, it amplifies these central probabilities and trims the ‘tails’ of the distribution. But it is in those tails that contains the rare, the quirky, the creative, and the outliers. With each generation, the variance drops. The model becomes more confident, but less diverse. It is inbreeding data until the digital equivalent of haemophilia sets in with the slightest error becoming fatal to the logic of the system.
In theory, the fix sounds easy. Do not inbreed, keep adding fresh human data. In practice, that is where the problem starts. Several analyses have pointed out that frontier models have already consumed much of the high-quality public text and code on the internet. AII companies have been rummaging through every data cupboard they can find, but most of them are bare now.
So, they have started ‘stealing’. . OpenAI reportedly used its Whisper system to transcribe over a million hours of YouTube video and feed those transcripts to its models. Training of image and video models like Sora has raised concerns that large amounts of copyrighted content from platforms such as YouTube and TikTok may have been scrapped without clear consent.
Now, if a new model scrapes the web, it is likely scraping an article written by ChatGPT, summarized by Claude, and illustrated by nanobanana. It is a Hall of Mirrors, disfiguring the output every time.
We have seen this movie before - with ‘free’ social media. As the oft-repeated saying goes: if you are not paying, you were the product. In the AI era: if you’re not paying for the AI, you and your behaviour are its training data. That would still be tolerable if our behaviour remained independently human.
But we are already letting AI shape what we read, watch, write and buy. Recommendation systems nudge our playlists and viewing lists, Copilot-like language models co-author our emails and reports, and AI-generated “slop” fills more of the web every week.
Put these two loops together and you get a nasty feedback system. First-generation models train on a mostly human internet. Those models then influence human expression, which becomes more AI-shaped. Everything starts averaging out as styles converge, images standardise, and code snippets, boilerplate and even legal clauses start to look alike.
The next generation of models trains on this partly synthetic, partly AI-influenced corpus. They are not just learning from us, but also from a world already bent towards them. The human is technically ‘in the loop’, but in reality we are amplifying the loop that leads to model autophagy.
AI learns from a human world that has effectively learned from AI. This is the dangerous feedback loop. If the model says “the sky is neon green” often enough, and humans start repeating it because they trust the model, the next model will treat ‘neon green sky’ as an established truth!
The risks are not just aesthetic. If models collapse, they don’t just produce boring images and generic prose, but they lose touch with the rare, unexpected, minority pattern. Those are exactly the edge cases that matter most when you use AI to triage patients, screen loans, or detect fraud.
Bhasmasura’s Digital Curse
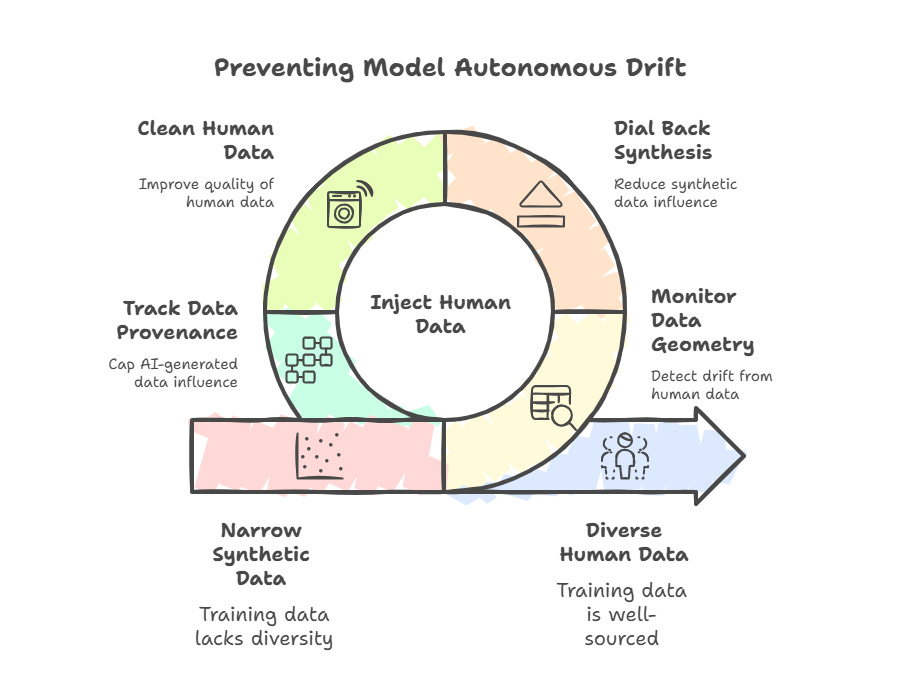
Can we prevent MAD? Well, people are trying. Researchers are trying to develop tools to measure the geometry of data manifolds and detect when the training distribution is drifting away from properly diverse human data. The UCLA group uses the shower metaphor. You turn the tap towards hot, scald yourself, correct back towards cold, overshoot again, then finally settle into a comfortable middle.
Training pipelines can do something similar by monitoring how synthetic and narrow the data has become and actively dialling back, injecting fresh, well-sourced human data as an anchor. Other approaches focus on cleaning human data rather than replacing it, and on tracking provenance so that we know what fraction of a dataset is AI-generated and can cap its influence.
But all of this is futile if the social and economic incentives point in the opposite direction. If every publisher is rewarded for flooding the web with cheap AI content, if every platform optimises for engagement rather than depth, and if every organisation treats AI primarily as a way to remove humans from the loop rather than upgrade them, then the technical fixes are akin to a shower thermostat in a house ablaze.
This reminds me of the original MAD, Mutually Assured Destruction, in the nuclear arms race. That surprisingly effective doctrine said that if both sides know that pressing the button destroys everyone, that knowledge will paradoxically keep the peace.
Model Autophagy Disorder is a quieter, subtler version of the same structural risk. This is not as much about blowing up the world, as it is about blurring it. If Model Autophagy Disorder is not checked, we do not risk a nuclear winter, but a true winter. A dystopian future where history, culture, and creativity are smoothed over into a dull beige, hallucinated, statistical average.
Indian mythology speaks of the story of Bhasmasura, the demon who was granted the power to turn anyone to ash by touching their head. In his hubris, he was tricked into touching his own head, consumed by the very power he sought to wield. AI, in its hunger for infinite data, risks becoming Bhasmasura, burning itself out by consuming its own tail.
Dear Jaspreet, thank you for bringing originality back into researched and thoughtful writing on AI. The way you weave together the two MADs, the Habsburg analogy and the Bhasmasura story with model autophagy, gradient descent and hypertuning is outstanding, it makes a very technical risk both accessible and hard to ignore. I thoroughly enjoyed the piece and will go back to read what I have missed so far on Dharma of AI.
The insatiable hunger for data was familiar; the idea that it could itself lead to a MAD like collapse was genuinely eye opening. I had assumed that data would more or less “grow with the need”, or that we would always find new seams to mine, not that the system could start poisoning its own well. I would be very keen to hear your take on how developments in Responsible AI and AI governance intersect with this risk and how far the current guardrails and regulatory thinking really go in preventing the kind of feedback loop you describe.